Exploring the Computer Vision Abilities from the Cloud Services that use Machine Learning
Empowering developers to understand the content of an image is now flourishing in the cloud space. There are so many powerful image analysis services that utilize the machine learning ability to let the developers to custom their models.
Here are some of the list of AI & Machine Learning products available in the cloud:
Microsoft’s Azure Custom Vision Service
Google’s Cloud Vision API/Cloud AutoML (Beta)
IBM Watson Visual Recognition
Amazon’s Rekognition (with the letter ‘k” instead of ‘c’)
Please note that there are many other services out there, but some don’t let you create your custom models.
The basic workflow for the process is that you want to create a model or a knowledge dataset that machine is used to recognize and identify the object presents in the image you later want to test. First, you upload several images contain the known object and then label them, then the machine begins to learn in the process called Training. At the end of training, a knowledge-based model is created, and the user can export the model to many formats like Tensorflow (for Android devices), CoreML (for iOS devices), ONNX (for Windows devices), and then it can be trained further or used by other applications. After the trained model has created, we can ask the machine to identify the target image that the machine has not seen before, and during the Inference phase, the machine is trying to identify the object with a probability of correctness.
The training process is the most computationally intensive step compared to the Inference since it is a process of developing an algorithm and it sometimes involves the deep learning using layered neural networks. Thus, the training process should be done in the powerful cloud computing servers and let the edge computing devices to do the Inference since it is less computationally intense And as a bonus, if the edge devices are equipped with GPUs, the process is further optimized. When selecting a cloud vision service, don’t overlook the ability to do an export of your model when you are selecting your cloud vision services. However, you need to know their limitations on what they can export as well. For example, if you are using Microsoft’s Custom Vision Service, it only exports the compact version, but that’s not all bad because it is suitable for mobile devices if it requires a real-time image classification capability and there is no need to send images over the network. However, the accuracy of identification is slightly less accurate than the complete version.
In this article, we are going to use Azure Custom Vision Service to explore the image recognition aspect of the machine learning. It’s free to use, and you do not need an Azure account so that you can play around on your own. In this demonstration, I want to identify a toy train, Thomas Train, using the Custom Vision Service, and to explore its capabilities and limitations when comparing to other toys.
1. Visit https://customvision.ai/
2. Sign in with a Microsoft login
3. Click on New Project to create a new project
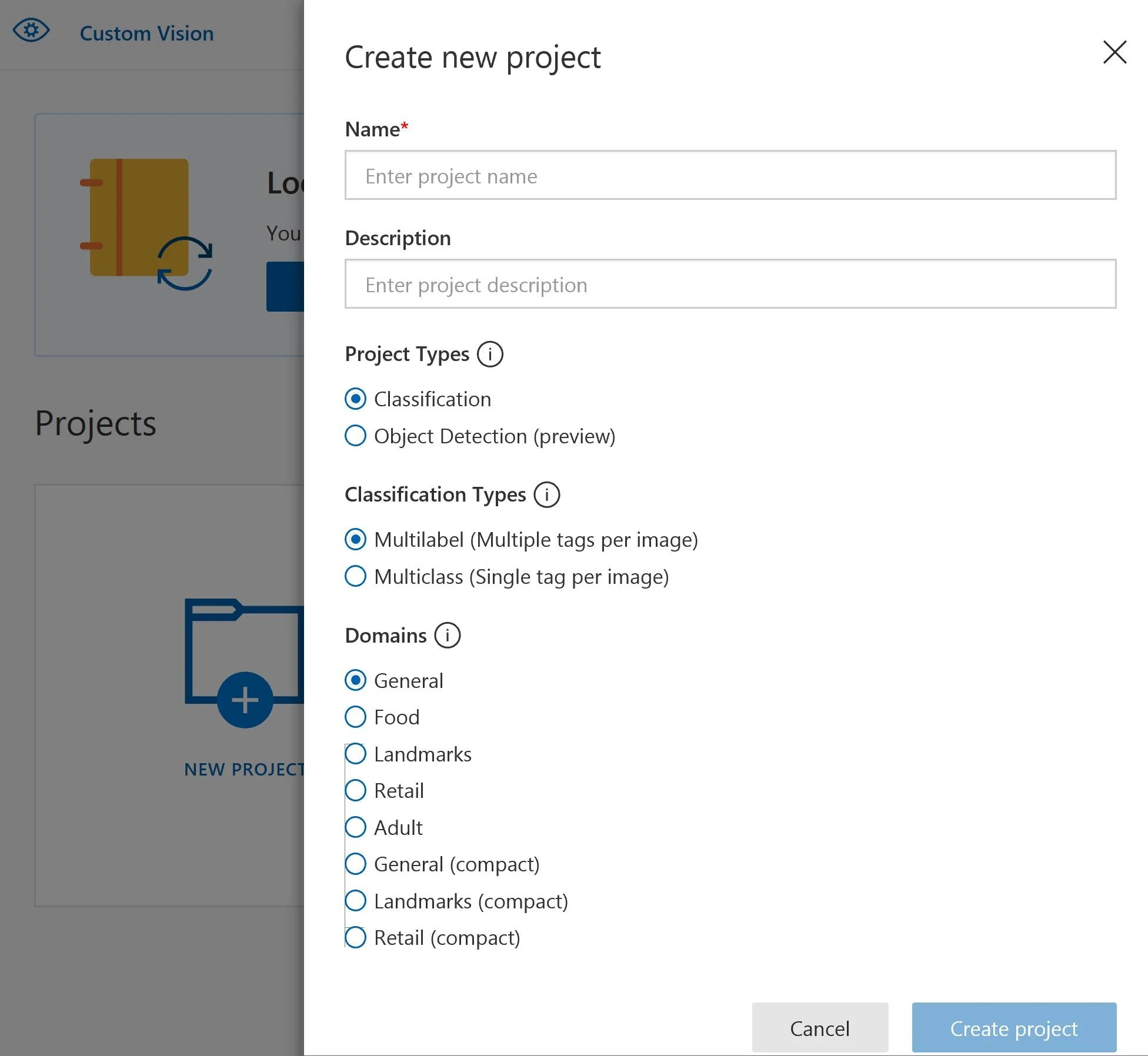
4. For your first project, you will be asked to agree to the Terms of Service by selecting the checkbox and then select the I agree button. The New project form will appear.
5. Fill out the new project form and click on the blue create project button.
6. Click on Add images button on the top and then select Browse local files.
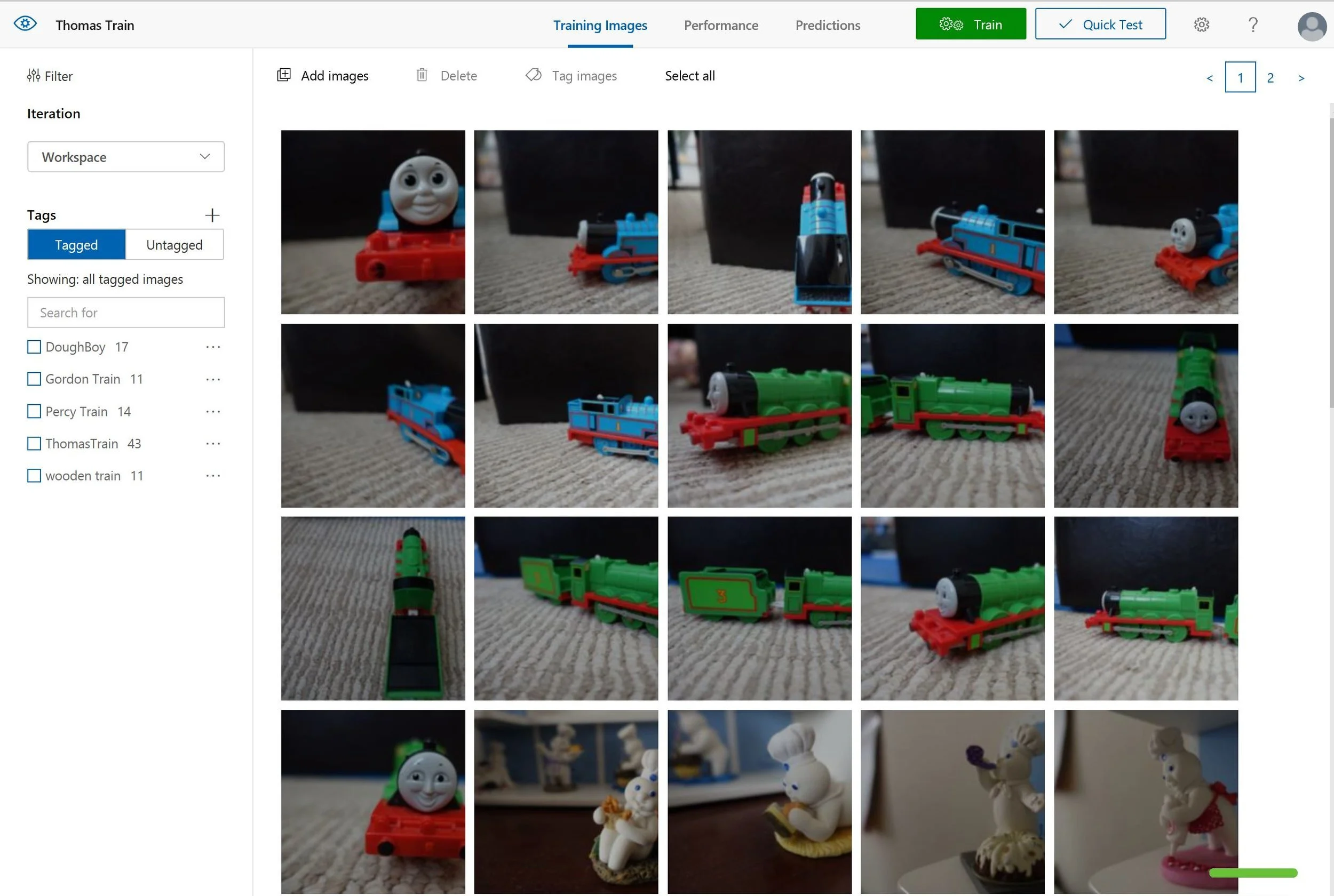
7. You should be able to add labels or tags to the images.
8. When it’s done, you should click on the green Train button on the top to begin training.
9. After training, the predictive model is created. You can click on the Quick Test button to upload the desired image you want to let the service to identify. You should use an image that you have not uploaded, or it’s not part of the training set, or else it’s too easy for the machine to do the test.
10. If you are not satisfied with the result, you should prepare more images, and upload new images to the service. You can repeat the training steps as it shows on the left in the Iterations list.
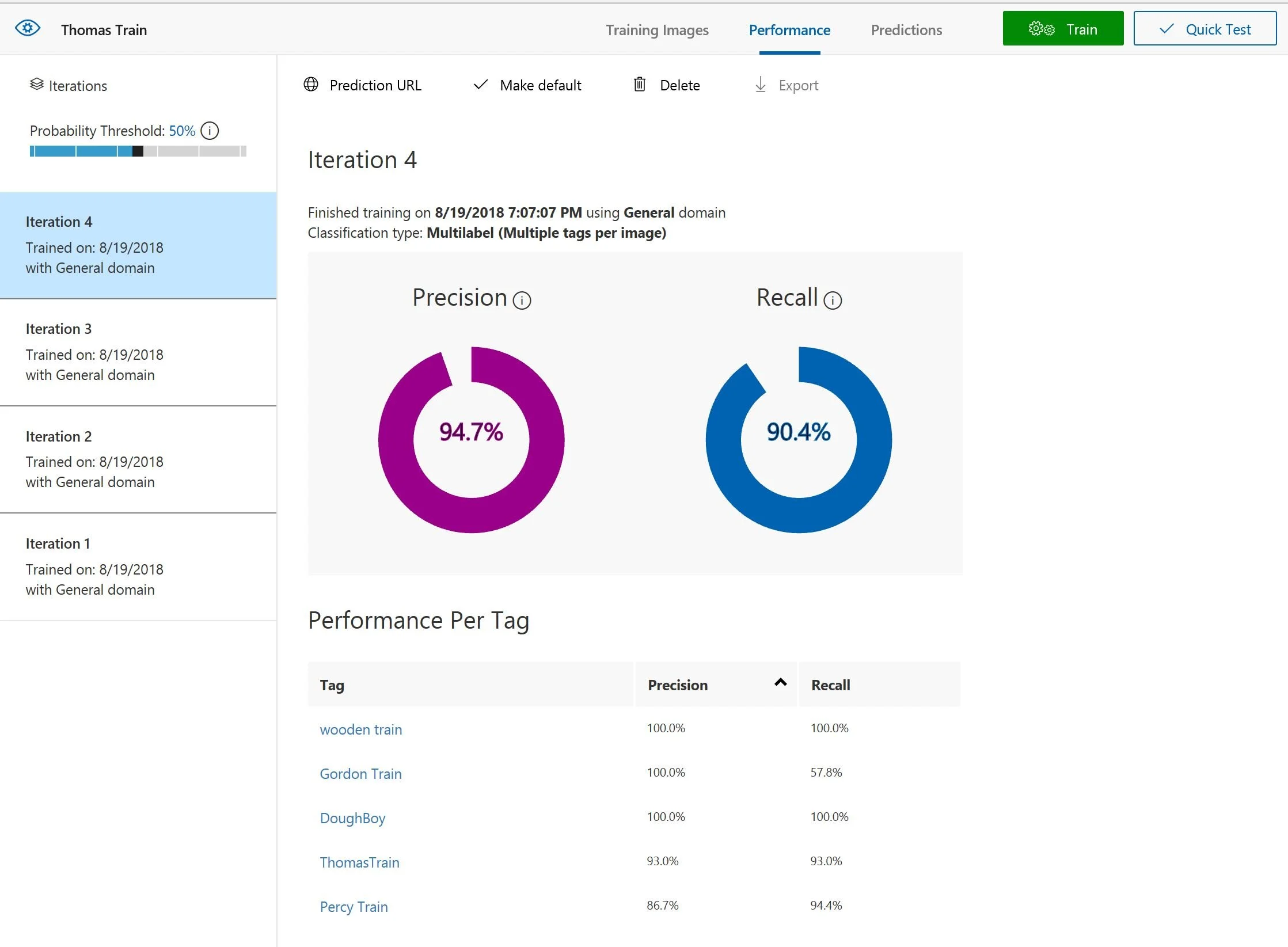
When you are complete with the training, you can export the model or use the REST API for your applications. When you click on the gear icon from the top, you can see two API keys in the Account section. One is for training API in which you can upload new images to do training using the codes instead of using the interface. The other API key is for predicting the image.
To learn more: https://docs.microsoft.com/en-us/azure/cognitive-services/custom-vision-service/csharp-tutorial
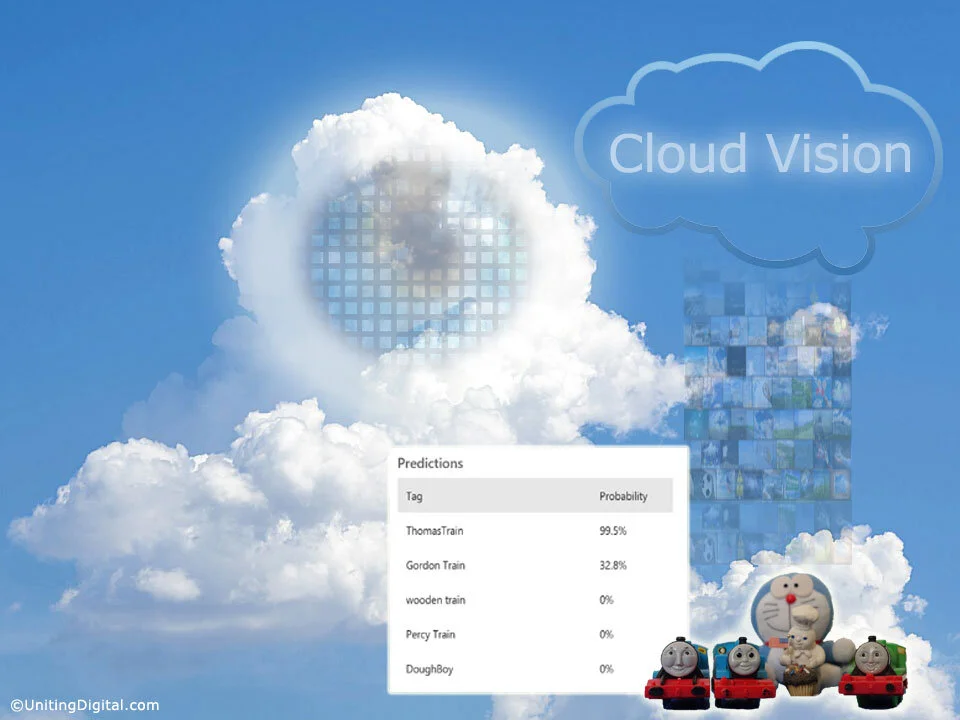
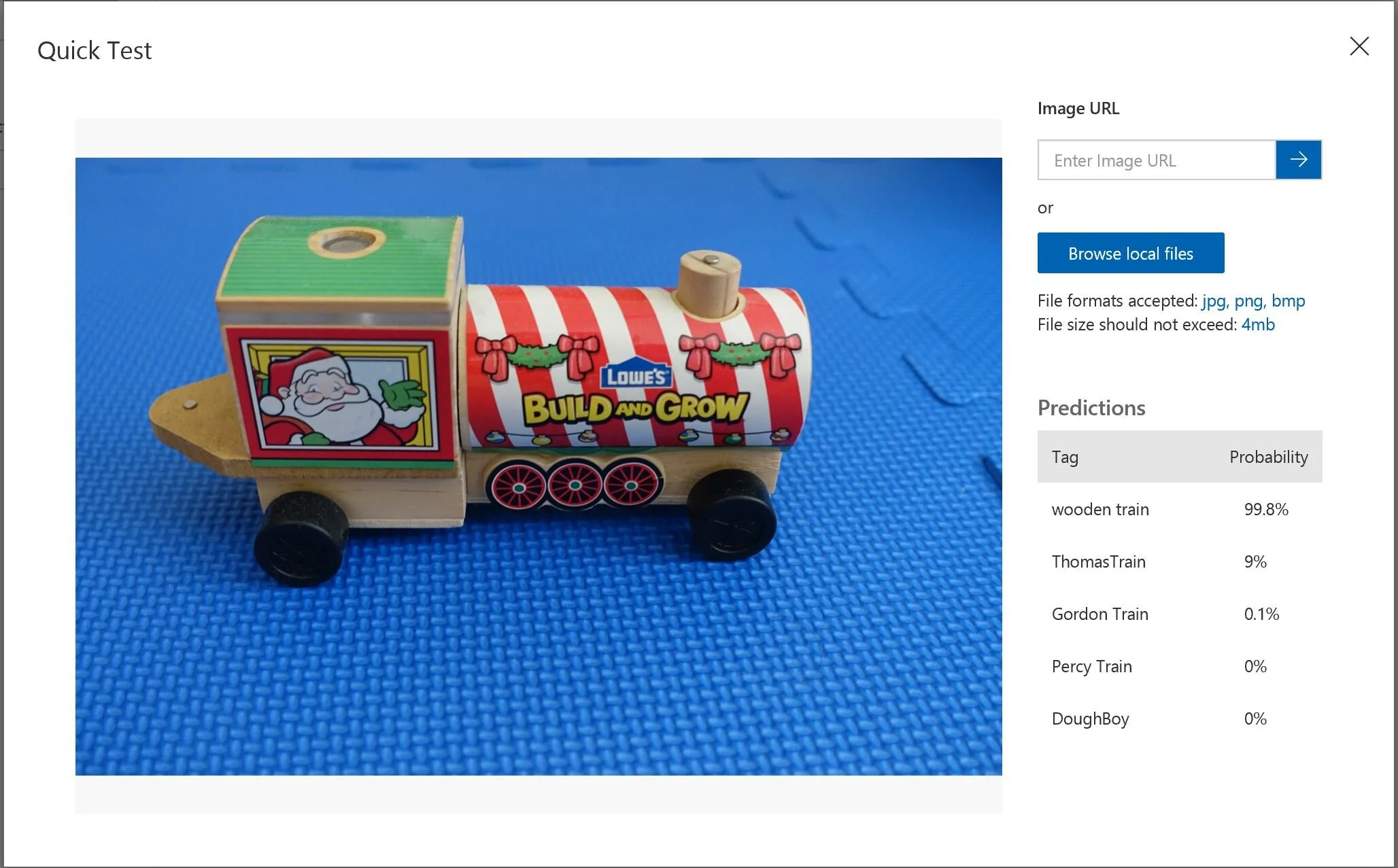
As you do more iterations and add more diverse images, you tend to get better results. In the end, it identified the wooden train from the other types of trains by a 99% probability.
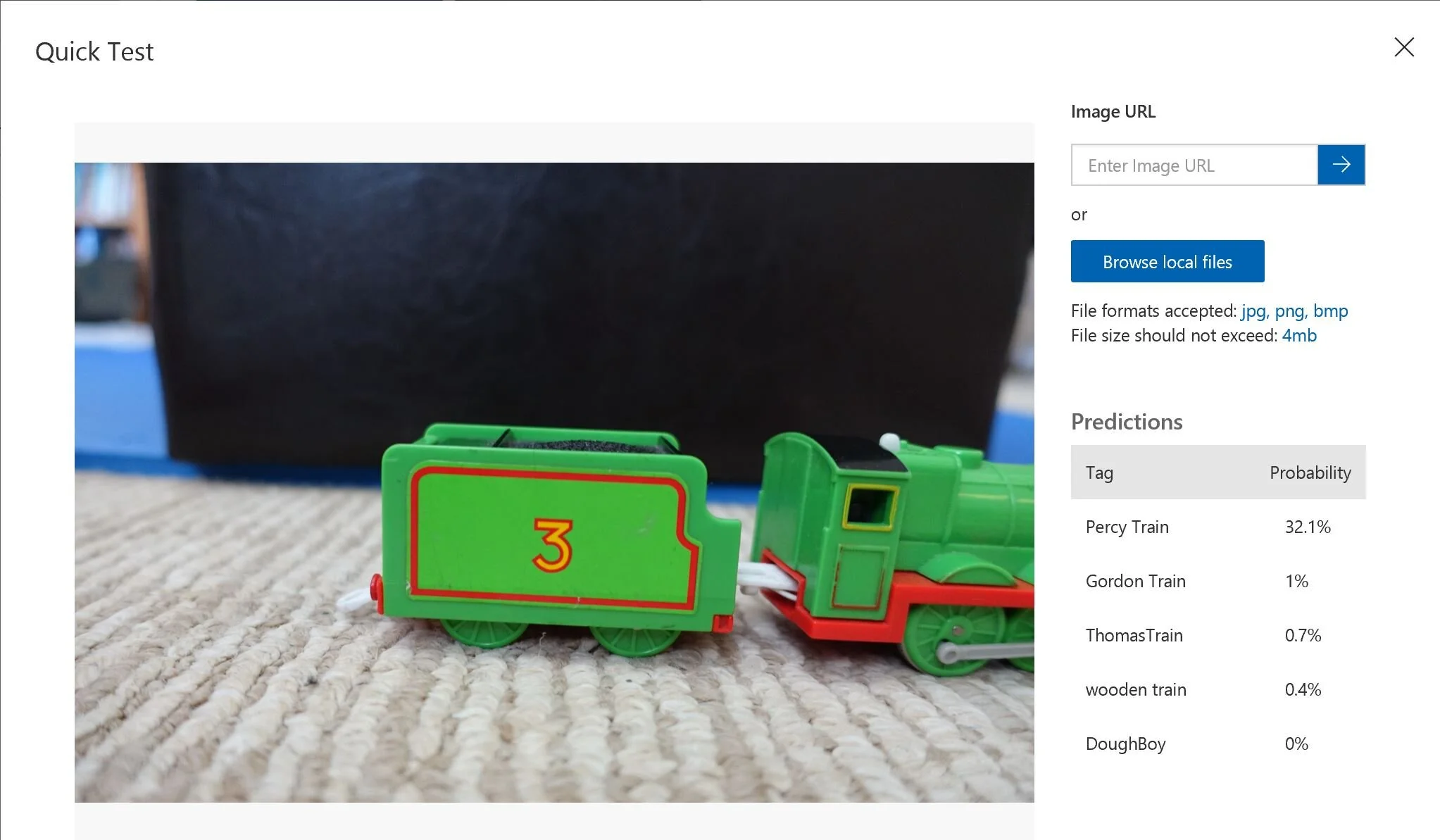
With the adequate number of Percy Train, it can still identify a partial image of Percy Train with the probability of 32%, where others are less than 1 %.
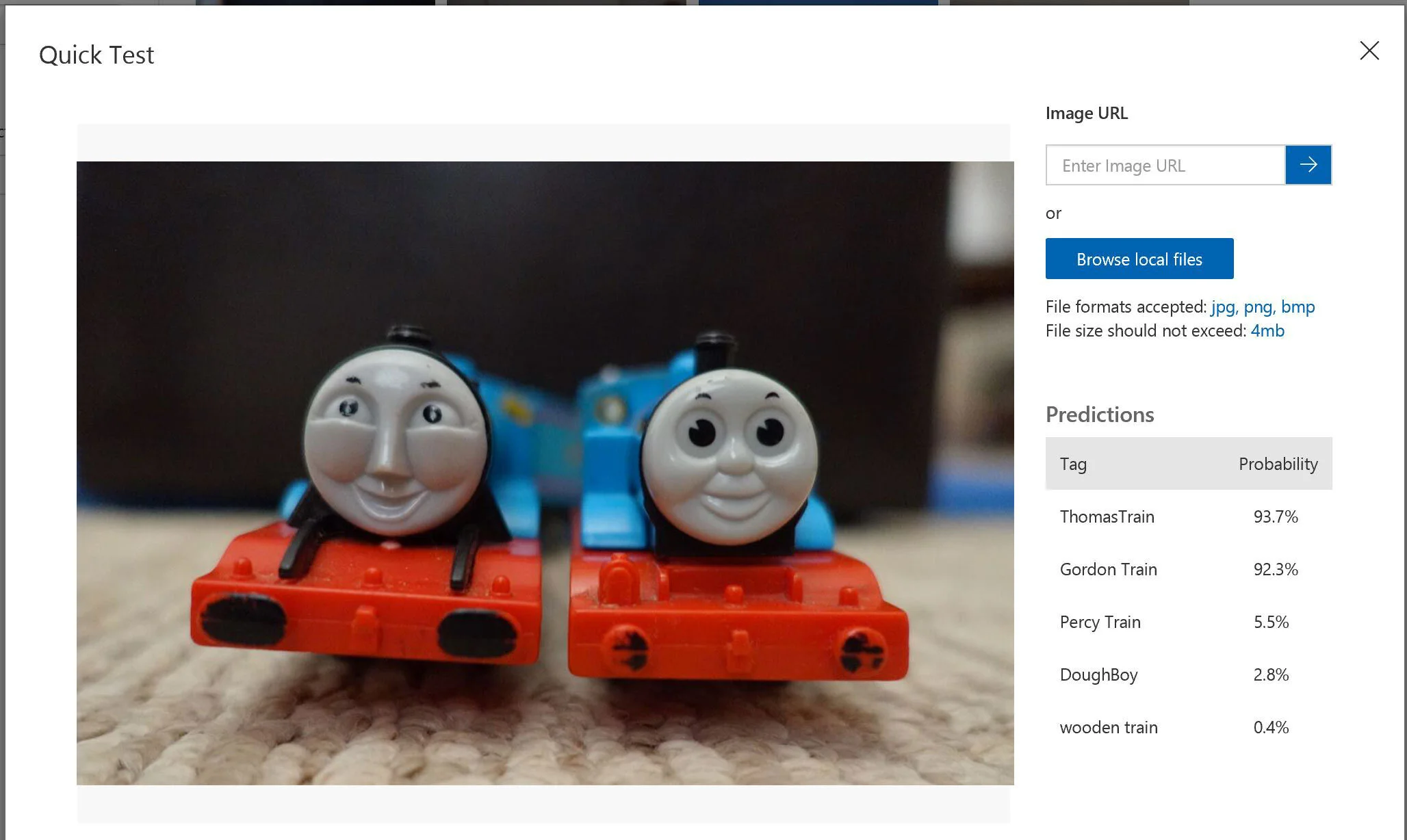
Since Thomas Train and Gordon Train are very similar in their looks, colors, and faces, it still correctly identified both with 92% of probability.
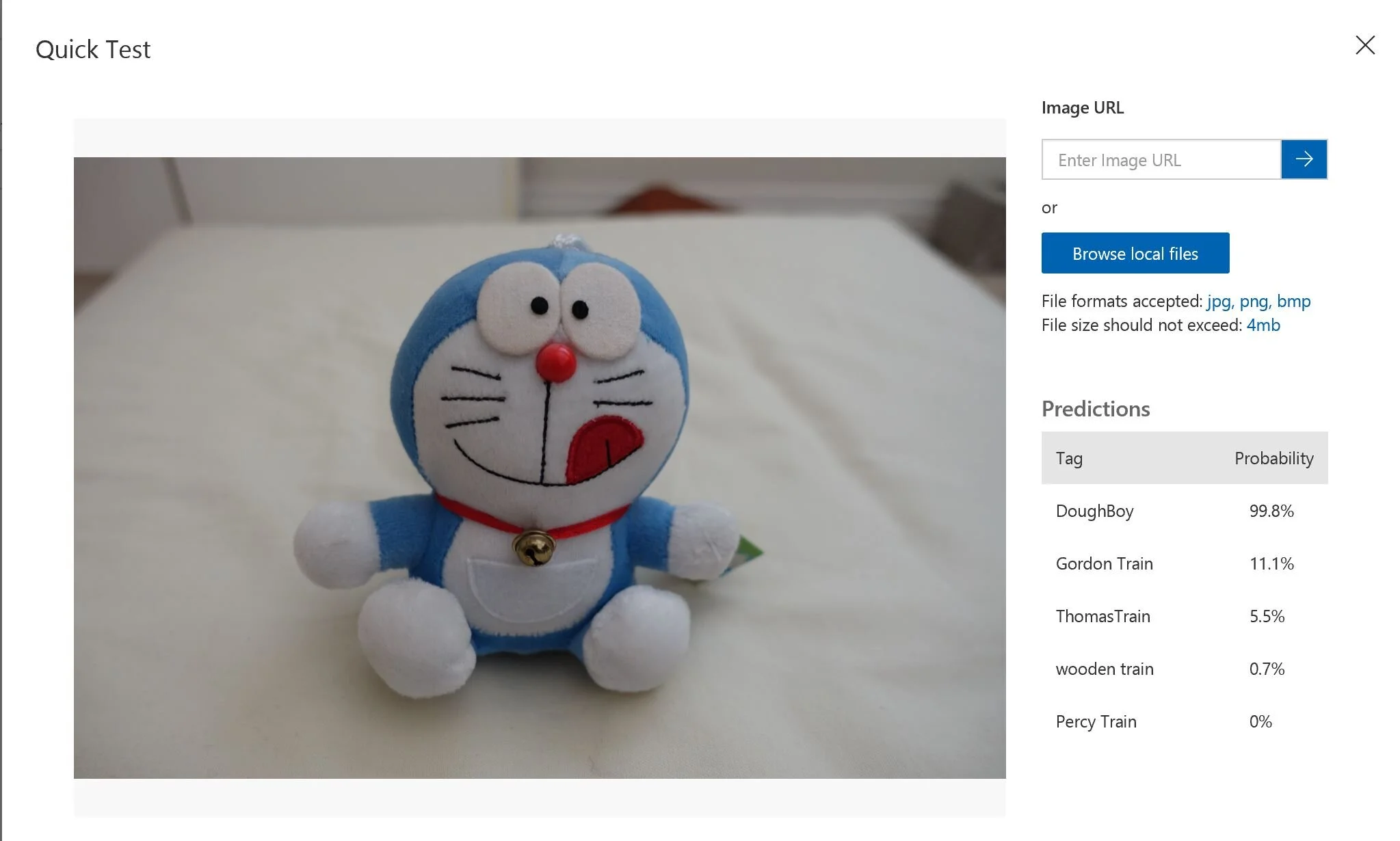
However, if we test an image with an object that is not in the collection, it throws off the prediction considerably. For example, I put a Doraemon toy, and it identified as Dough Boy with a high 99.8% of probability. For humans, if I never saw that toy before, I would say none of above, instead of trying to guess one from the collection. There is still a long way to perfect the recognition capability but making the custom vision this easy for developers is unthinkable in the past.